When digital APS-C cameras started appearing on the market in the early 2000s, conventional wisdom was that you needed film (or full frame) for wide angle work. In that environment this made sense – almost all lenses were made for full frame, which meant a crop factor when put on an APS-C body. Thus to get the widest possible image from a lens, you needed a full frame sensor.
This changed when the Canon 10-22mm and other wide lenses with an APS-C-sized image circle were released, as these are much wider without being ridiculously large. So if you still think full frame is better for wide angle, please think again. Other than the natural resolution and high-ISO advantages of the sensor, there is nothing inherently superior about full-frame cameras for wide-angle work, and wide-angle DSLR lenses in particular have a substantial disadvantage to mirrorless when it comes to size.
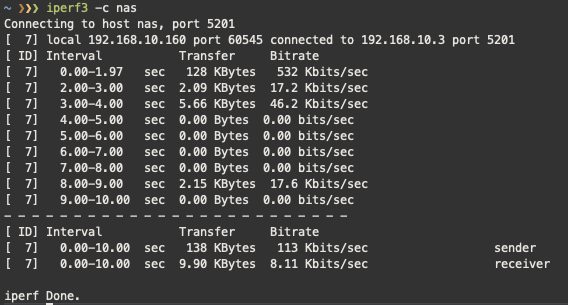
My partner and I live in a 2-bedroom flat with our very young daughter. After a couple of weeks of working from the living room, which is where the WiFi is, and where I typically keep my computer, I decided, for the good of our relationship, to move my office to the spare bedroom.
There’s just one problem:
I can connect to the Wifi, but performance is abysmal
I’m not alone in spending a lot more time working from home recently, and if my Slack calls at work are anything to go by, I’m also not alone in struggling with poor WiFi reception. Urban areas tend to be densely packed with WiFi signals at the best of times, let alone while everyone’s cooped up at home full-time.
In my case, the WiFi connection in the spare bedroom is totally unusable for work, but continuing to work from the lounge would risk my relationship (and possibly my general safety).
It’s hard to go past eBay for a second-hand laptop (full disclosure – I own some shares in eBay). There’s a huge range, and it tends to be the outlet of choice for ex-corporate machines which are replaced on a regular cadence – more regularly than most consumers would replace theirs.
But buying a second-hand Latitude can be a bit of a lottery if you don’t know what you’re getting, as the lines are confusing with many different models. Here I’ll try to break it down, so you can make a more informed decision.
I’ve focused on small and light models, as that is what I bought for myself and thus was what guided my research. If you’re interested, check out my article on upgrading to a Latitude 7300 from a Macbook Pro.
The last time I upgraded my laptop, I went from a Dell Latitude E4300, to a late-2013 13″ Macbook Pro. That was six years ago!
I didn’t expect to get anywhere near 6 years from the mac, as it’s not exactly upgradeable (you can replace the SSD, but that’s it). Modern macbooks are even worse – even the SSDs are soldered. Thus, you’d better anticipate your needs over the lifetime of the machine, because once you click buy, that’s the specification it will have for life.
The Latitude E4300 I had before it lasted 5 years, which was also very good. Back then, laptop technology was improving noticeably with each generation, but it’s fair to say that Intel’s dominance and complacency in the x86 CPU market resulted in marginal gains between generations. You could skip 3 generations and barely notice a performance increase.
Fortunately things have now changed. AMD’s release of its Ryzen processors a couple of years ago gave Intel a much-needed kick, and now we suddenly have 4 and 6-core designs in 15W power envelopes. The improvements over Sandy Bridge and Haswell are now substantial and easily warrant an upgrade.
Thus, the Macbook is starting to feel slow. It’s specs are:
Core i5 4288U 2.6ghz (dual-core)
8GB ram
512GB SSD
8GB of ram is what I’d consider the bare minimum – acceptable for browsing but not really software development or content creation. The 512GB SSD is still serviceable, but at ~700MB/s read and write, it is rather slow compared to modern NVME drives which can top 3,000MB/s in ideal conditions. But the performance of the 28W dual-core i5 is probably what’s driving this upgrade the most.
So in late-2019 I started shopping for a new portable laptop to replace the macbook. My requirements are:
13-inch form-factor
At least 4-cores
At least 16GB ram
At least 512GB of SSD storage (pref 1TB)
To cut a long story short, this time around I have gone back to the future and bought a Dell Latitude instead of another Mac.
At work we have a very large and highly active repository which contains the majority of our company’s code. Despite regular pruning and garbage collection, this repo can get rather slow, and the asynchronous git commands run by zprezto often get in the way of actual work, like commits, by holding locks at inopportune times.
Thus, selectively disabling the git prompt for some repositories makes a lot of sense, as the cost outweighs the benefit if it’s constantly getting in the way.
I couldn’t find direct instructions for doing this online, but fortunately the code is easy to parse; there’s a check for a git config option here.
As git configuration can be on a per-repository basis, all you need to do is run the following command from your giant repo to disable the git prompt:
git config --bool prompt.showinfo false
And you’ll still see the git status information on other repositories without this config option.
Note, this will obviously work only for themes that use the built-in git module, but that should be most of them.
FlexPlus is Nationwide’s premium paid-for current account. For a fee of £10, which increased to £13 in 2017, you got mobile phone insurance, travel insurance, no-fee ATM withdrawals overseas, and 3% interest on balances up to £2,500. It’s been MoneySavingExpert’s recommended premium account for years now, and until recently was a great deal. Possibly a bit too good to be true.
A while ago I wrote a post about my backup solution and replacing Crashplan – a once great product I was a happy user of. It served pretty much all my backup needs in one product, but alas it was too good to last.
Eventually I settled on Duplicati on my home server backing up to Backblaze, and Urbackup to back up my various devices to the NAS. But since then a few things have changed:
The upgrade to Ubuntu 18.04 broke the Urbackup installation on my server. I never really got around to fixing it, so my device backups have been manual. Fortunately the server hosts the important stuff, and I don’t keep much on my devices that aren’t saved elsewhere, but it’s still not ideal.
Perhaps somewhat mitigating this for Mac clients, the Samba project released version 4.8.0, which includes support for MacOS time machine (see “Time Machine Support with vfs_fruit”).
Dropbox have started being dicks.
… Dropbox?
Er, yeah. Despite writing “I think that you should never use Dropbox for anything remotely private or sensitive”, words that I stand by today, I have not only been using Dropbox… but for private and sensitive things.
Today I read an article on Arstechnica (Right-wingers say Twitter’s “bias” against them should be illegal), and, as hot-button political topics such as this so often do, it spawned an interesting comment thread. Ars is a thoughtful, rational, and evidence-based site, so it should come as no surprise that the majority of commenters are of the same persuasion. So much so that the comment threads are occasionally more interesting than the original article.
The argument you often hear from the far right, is that refusing to publish or listen to their hate-speech amounts to censorship. By “censoring” their speech, the supposedly “tolerant” society is behaving like the Third Reich. Godwin’s law aside, this latest attempt by Trump and Co. to stop Twitter and other social media companies “silencing conservative voices”, runs along similar lines; they are arguing that bias in suppressing “conservative voices” should be illegal, in the name of free speech.
For some time now I’ve been a happy user of Adobe Lightroom. I brought it back when Lightroom 4 was released, skipped version 5, then paid to upgrade to 6.
Since then, Adobe has discontinued the perpetually licensed version. The only way to legally obtain Lightroom is by paying £120-240 per-year for one of their Creative Cloud subscriptions.
Unfortunately the new subscription model is a rather poor fit for my needs.
I want to state upfront that I don’t object to subscription-based pricing models for software in general. It makes a lot of sense from a development point of view, as maintenance and support costs don’t go away once the product is shipped. But in my opinion Adobe has reached too far, and is trying to steer customers towards cloud solutions for reasons that don’t really align with their best interests.
My reply to the answer thanked him for it, but mentioned that I think systemd is the right place to do this “sort of thing”. In reply to my reply, he told me that systemd is “absolutely the wrong place” to do this sort of thing, which is pretty strong language!
I think we’re approaching this from different perspectives here, so let’s break the problem down in general terms.