My experience running IT infrastructure at home, with some recommendations for
anyone starting out on their Homelab journey.
I’ve been running a home server of some kind for more than 20 years. It started when I was at university, hosting a website on an old PC to share party photos (this was in the days before social media). It worked, but was madness in hindsight. The intent wasn’t to make the photos public (it was password-protected), but I was publishing PHP applications (Drupal and Gallery) on the public internet with a “make it work” Apache configuration, whilst being blissfully ignorant of the security risks. That code running today would be compromised in seconds.
Since I left university, all my home servers have been lan-facing only – no external ports. My approach has always been fairly minimalist, mainly because I’ve moved around a lot and never had the spare space to keep lots of IT hardware. I went from flatting in Christchurch, to flatting in Auckland, to living in London where space is at a premium. It’s only in the past year that we’ve brought a house and I’ve been able to consider a more expansive setup. However playing with enterprise hardware doesn’t excite me the way it used to, so I lean heavily towards the quiet and energy efficient, which for the most part means lower-power enthusiast-grade gear.
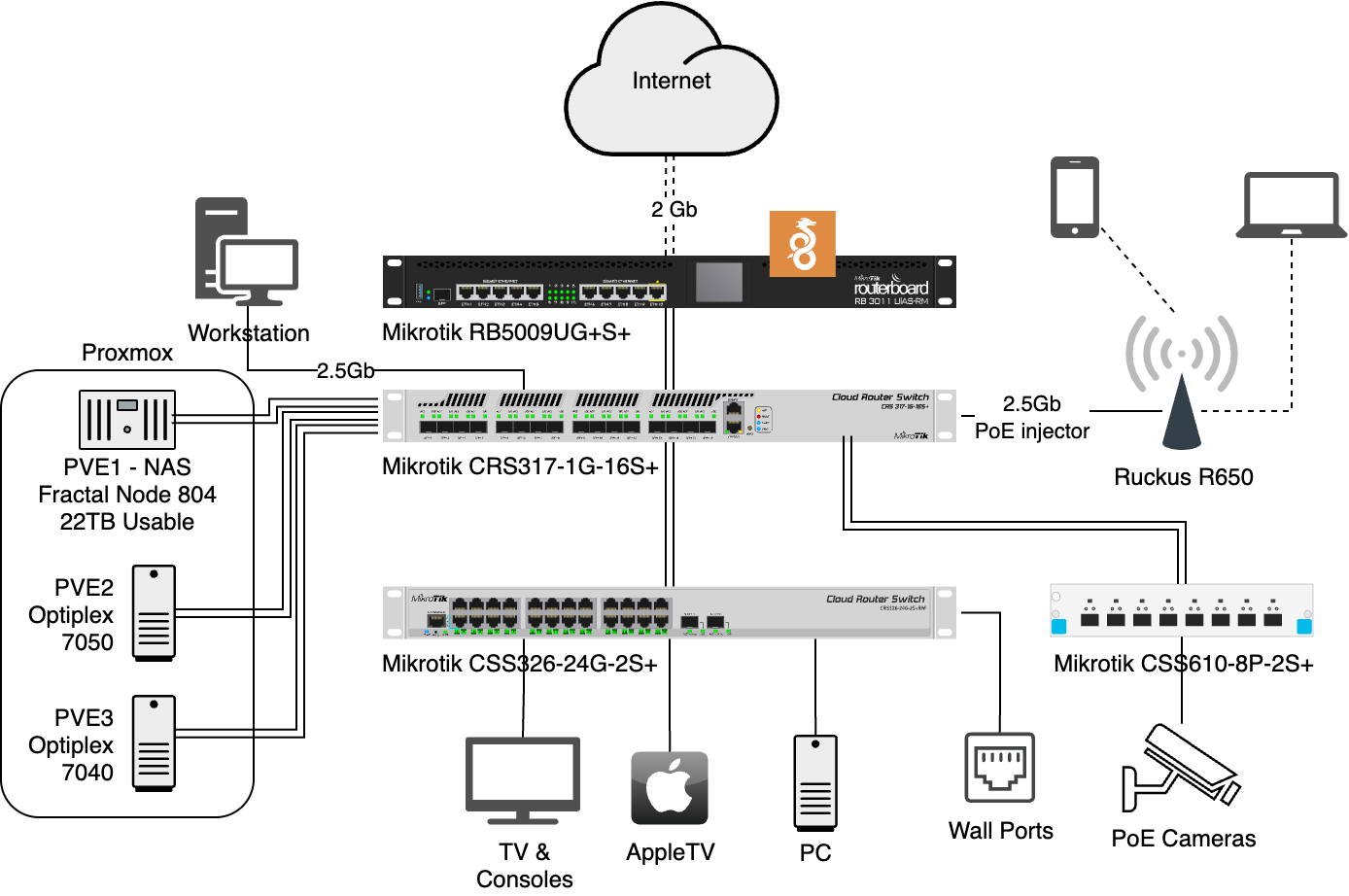
Of course those that know me would scoff at calling my setup minimalist, because by the standards of normal people it’s anything but. I have 3 rack-mounted switches (all connected with 10Gb uplinks), 3 PCs cosplaying as servers, a router and an ex-enterprise wireless access point all sitting on the “coms shelf”. Most people just have the WiFi router their ISP supplied, plus a couple of laptops, phones and maybe a desktop in the office.
It wasn’t always this way though, my home network has evolved over the years, and will no doubt continue to do so. So consider this a snapshot in time of my personal learning.
Continue reading